- Jh123x: Blog, Code, Fun and everything in between./
- My Blog Posts and Stories/
- Winning Typeracer every time/
Winning Typeracer every time
Table of Contents
Want to win at typeracer but you type too slowly?? Have some spare time to learn programming? Then this is the right place for you. In this post, I will be showing you how to automate typeracer using python and pyautogui.
Back story #
While I was on my exchange program, my friends and I came across a game known as typeracer.
It is this game where everyone types a passage and the person who finish typing the passage the fastest is the winner of the race. That sounds like something that can be automated :D. So that’s what I have decided to do.
To view the full github repo click here
The main roadblocks that we have to overcome first
- The text cannot be copied off the site. It was disabled
- We need a way to enter keystrokes into the system
Overcoming the text not being able to copy the text. #
When I saw that it cannot be copied, I thought of 2 different solutions to solve this problem.
- Taking the html through automated browsers (Selenium)
- Using OCR to recognize the image.
I have decided to go the second route instead of the first as we will be able to control the browser after that.
Because of that we have to complete the following steps to complete this.
- Screenshot code to screenshot the passage
- Using OCR to recognize the character at close to 100% accuracy.
For taking the screenshot, I have decided to go with pillow’s ImageGrab. It takes a bunch of coordinates and it will screenshot the section of the screen.
After taking the image, the screenshot will be fed into pytesseract where it will hopefully spit out the correct words :D.
A way to enter keystrokes into the system #
There are many libraries that can do that, but I have decided to go with pyautogui.
The library is very easy to use. In this case, all we need to do is to call the typewrite method and key in the words that we want to type. For example. typewrite("Hello world") will key in Hello World as if you are typing on the keyboard.
What happened after that #
Now that those 2 problems have been solved, it should just work out right??
Sadly Nope TT.
After solving 2 problems, 3 more problems came up.
- The OCR is not accurate enough to detect all words correctly.
- There are option text below
- There is no way to stop the program once there is a mistake.
Solving the problems #
To debug this problem, I have decided to check the screenshot. It was very colorful and there are things getting underlined and options having words.
Lucky for me there is an option to restrict the word space. Using tesseract_config = r"""-c tessedit_char_whitelist="0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ ,:.-'?" """ and passing the config into the program, the character set will be restricted to 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ ,:.-'?.
This has increased the accuracy up a significant amount, but it is still not enough.
To make the detection more accurate, I gray-scaled the image before feeding it into pytesseract. Lucky for me after I have done that, the accuracy was good enough to detect the text accurately.
Now that the text is detecting accurately, we need to deal with the extra text options below. Another stroke of luck, there is an additional line between the text and the options. So all I had to do was split based on that and ta da it is finally working!
Conclusion #
Now just watch me rekt in typeracer right?
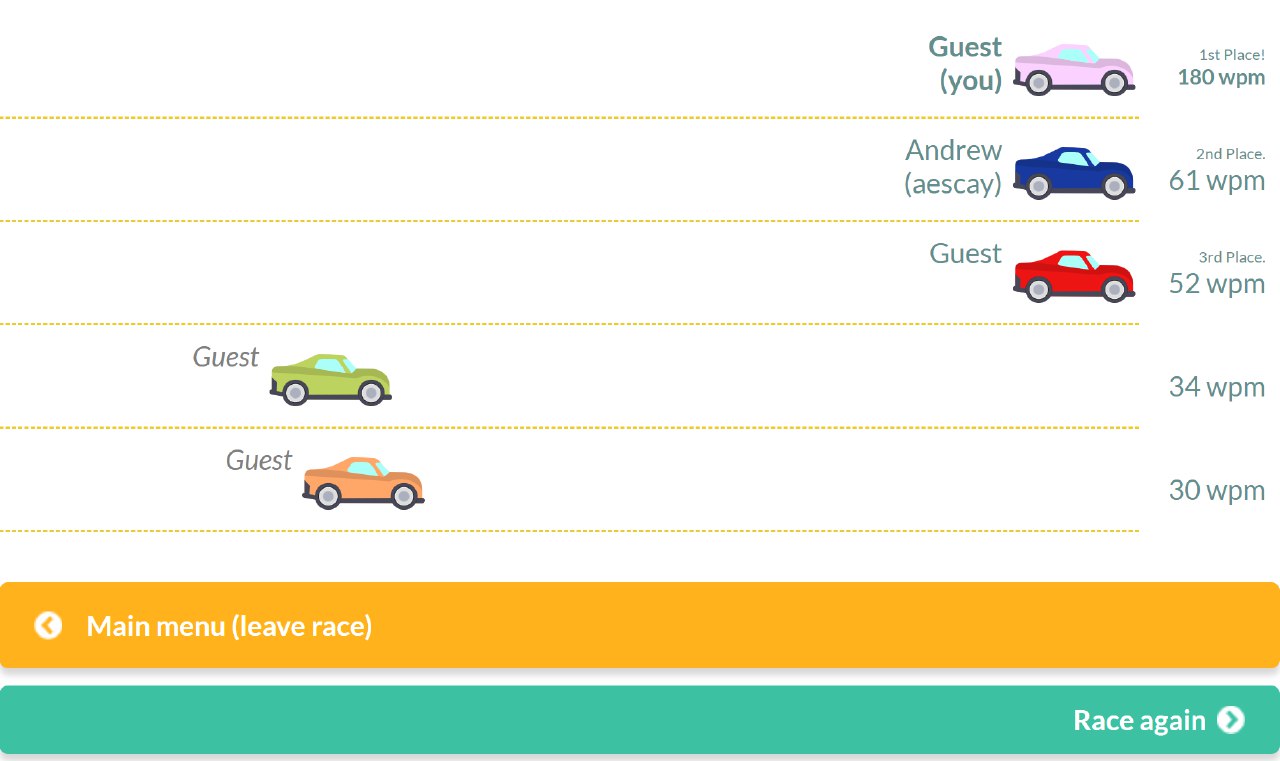
Well partially, after I run the code, and getting an amazing 180WPM, the website decided to test me to see if I was cheating. Sadly for me I cannot type in those speeds and the website is showing an image where the OCR cannot detect any words TT.
Welp I guess that was fun…..
Maybe next time we can develop a way to bypass that as well.
Here’s to automating even more stuff :D.